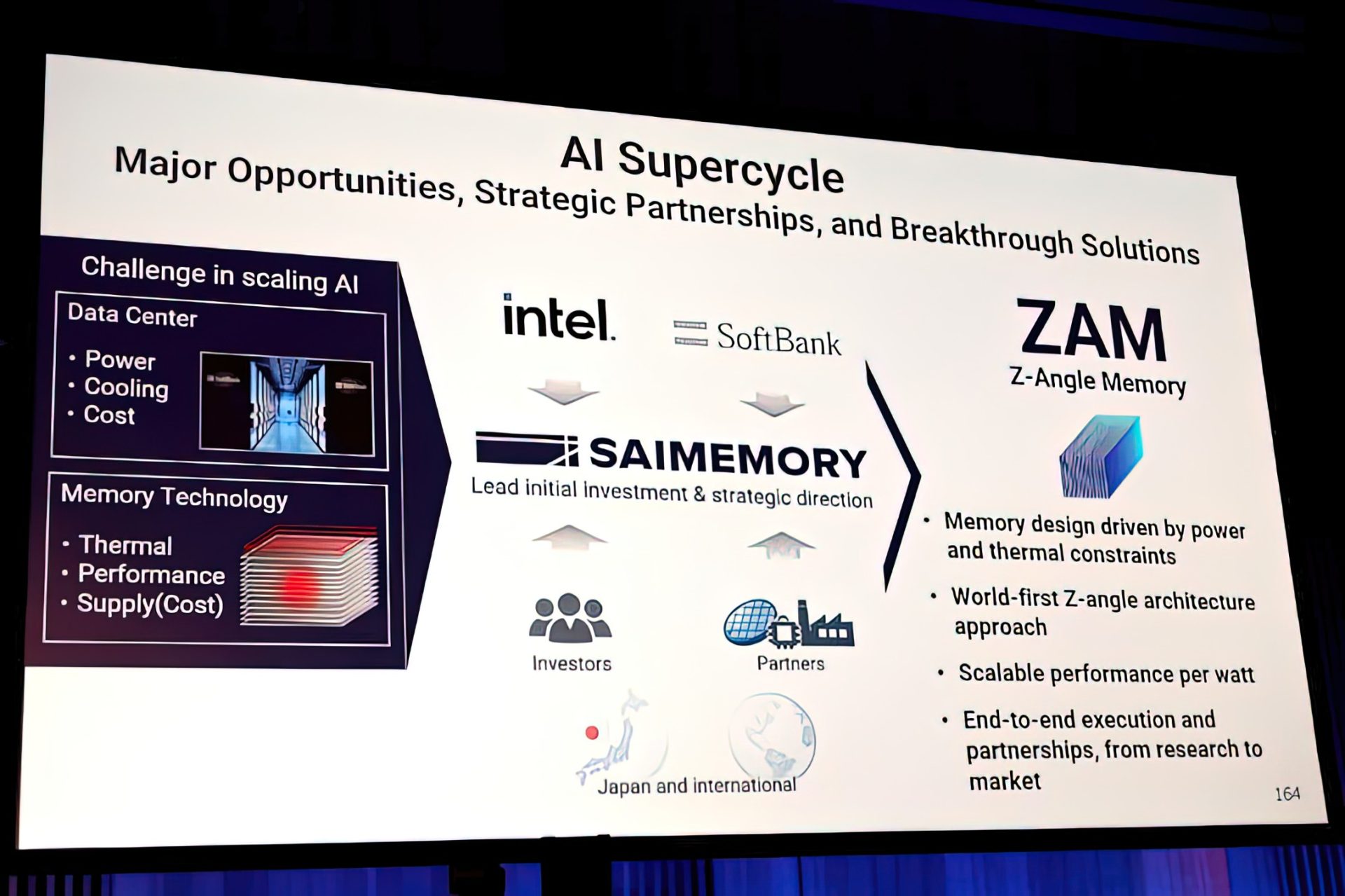
Intel is getting close to finalizing a new memory technology called Z-Angle Memory (ZAM), and it’s being positioned as a serious alternative to High Bandwidth Memory (HBM) for the next wave of AI hardware. Developed in collaboration with SoftBank (through its SAIMEMORY subsidiary), ZAM is designed to deliver high bandwidth and high capacity while keeping power use and heat under tighter control—two pain points that become harder to manage as HBM continues to scale.
What’s turning heads is the performance target. Freshly shared details indicate ZAM is aiming for roughly double the bandwidth of HBM4, putting it in the same conversation as even more advanced HBM variants expected later. While that sounds aggressive, it’s important to note the timeline: ZAM is not expected to reach production until around 2028 to 2030, so this is still a forward-looking technology race rather than something that will land in GPUs or AI accelerators next year.
A big part of ZAM’s pitch is its physical design. Intel’s ZAM demonstration uses a 9-layer stacked structure. In this setup, one stack contains eight DRAM stacks with ultra-thin silicon layers between them—about 3 microns per layer—plus a primary substrate that includes a single logic controller managing the full stack. The approach focuses on dense vertical stacking, which is increasingly critical as AI workloads demand more memory capacity close to the compute.
The interconnect design is also a key ingredient. ZAM uses three main TSV (Through-Silicon Via) layers, and each layer reportedly carries about 13.7K TSV interconnect paths using hybrid bonding. Capacity is listed at about 1.125 GB per layer, which adds up to roughly 10 GB per stack and around 30 GB for the full package described in the preview. Physically, the stack measures about 171mm² (roughly 15.4 x 11.1mm). On the bandwidth side, ZAM is described as delivering about 0.25 Tb/s per mm², translating to approximately 5.3 TB/s per stack.
So why does this matter when HBM is already the standard choice for high-end AI accelerators and GPUs? Because HBM’s growth brings engineering tradeoffs. Higher bandwidth and bigger stacks can mean more heat, more power draw, and increasingly complex packaging constraints. ZAM is being designed to confront those issues directly by focusing on three main goals: high density, very wide bandwidth, and lower power per bit transferred. Its vertical structural approach is also presented as a thermal advantage, improving heat dissipation without relying on routing through traditional wiring layers that can contribute to heat buildup.
Here are the main advantages being highlighted for ZAM in its current form:
– Higher bandwidth density, around 0.25 Tb/s/mm²
– Lower power consumption, with an emphasis on reducing data transfer energy
– Better thermal behavior, enabled by the vertical architecture
– Extremely high stacking potential, using ultra-thin silicon layers and via-focused TSV implementation
– Advanced scaling features, including magnetic field coupled wireless I/O and modern bonding approaches
– A strong focus on AI workloads, especially as generative AI continues pushing memory bandwidth and capacity requirements
Looking further ahead, the broader vision for ZAM is tied to what’s described as 3.5D packaging. The idea is to bring vertical and horizontal integration together on a single substrate—combining high-bandwidth memory stacks with elements like power and ground rails, silicon photonics, and legacy I/O. If that packaging strategy matures as planned, it could help solve multiple bottlenecks at once: bandwidth, power delivery, and data movement between compute and memory.
For now, ZAM remains a promising concept that’s moving closer to completion, with more technical detail expected to be revealed publicly at VLSI Symposium 2026. But the real test will be adoption. To truly compete with HBM, ZAM will need to prove itself in real hardware platforms, at real volumes, under the demanding conditions of modern AI training and inference. With AI markets accelerating quickly, any memory technology that can deliver higher bandwidth with lower power and better thermals will have a strong opportunity—if it can make the leap from research to production.