Artificial intelligence is moving into a new era where “inference” is taking center stage, and it’s quickly changing what companies buy, build, and optimize. At AI Expo Taiwan 2026 on March 25, Winston Hsu highlighted a shift that’s becoming impossible to ignore: the biggest pressure on AI infrastructure is no longer just training massive models from scratch. It’s running those models at scale, serving real users, in real time—efficiently and affordably.
For years, the AI conversation has been dominated by training. Training is the expensive, compute-hungry process of feeding enormous datasets into powerful hardware until a model learns patterns well enough to perform tasks like writing, translating, analyzing images, or generating code. That phase isn’t going away, but it’s no longer the only—or even the primary—source of demand. As AI tools spread into everyday business workflows and consumer products, inference is becoming the constant, ongoing workload that never stops.
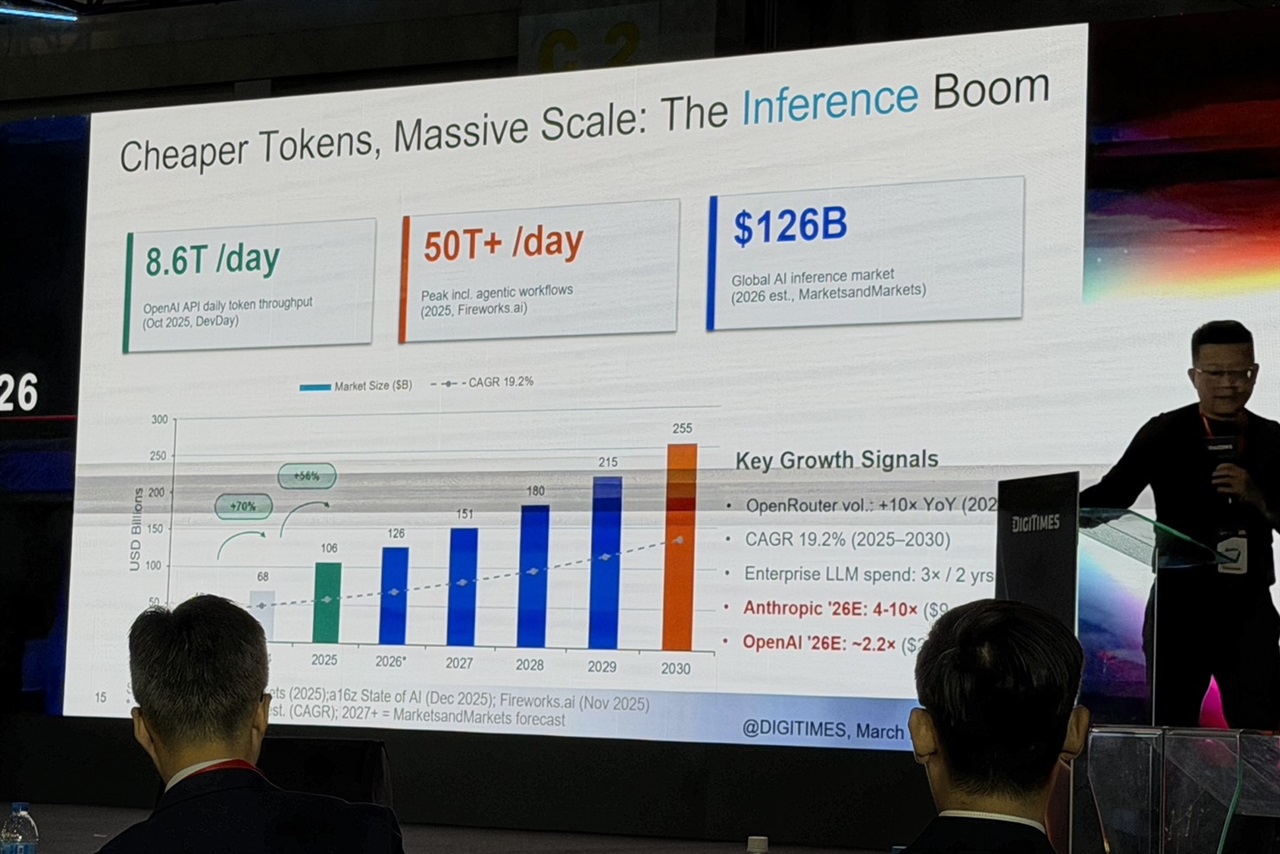
Inference is what happens after a model is trained: it’s the moment an AI system answers a question, summarizes a document, detects an object in an image, or generates a response in a chat. Do that once, and the cost is manageable. Do it millions or billions of times a day across apps, search features, customer service agents, on-device assistants, and enterprise automation—and inference becomes the dominant cost center. This is why the industry focus is shifting toward scaling AI usage, not just building bigger models.
What’s accelerating this change is the reality of rising costs and tightening memory limits. The hardware needed to run advanced AI isn’t just expensive to buy—it’s expensive to operate. Power consumption, cooling requirements, rack space, and data center capacity all add up quickly, especially when organizations want low latency and high reliability. The more AI becomes a default feature rather than a special project, the more those day-to-day inference costs matter.
Memory constraints are another major factor reshaping strategy. Modern AI models, especially large language models, are not only compute-intensive—they’re memory-hungry. Running them smoothly requires moving and storing huge amounts of data quickly, and memory bandwidth can become a bottleneck even when compute resources are available. As AI deployments expand, optimizing how models fit into memory, how fast data moves between memory and processors, and how efficiently hardware is utilized becomes just as critical as raw performance.
This new phase is pushing AI infrastructure decisions in a more practical direction. Instead of chasing the largest possible training runs, many organizations are prioritizing approaches that reduce inference cost per request, improve throughput, and keep response times fast. That can influence everything from how models are designed and compressed, to how workloads are distributed between cloud and edge devices, to what kind of accelerators and memory configurations are most valuable for real-world AI applications.
The bottom line: AI is maturing. The industry is moving from an era defined by training breakthroughs to one defined by deployment at scale. As inference becomes the main driver of computing demand, the winners won’t just be those who build the smartest models—they’ll be the ones who can run them efficiently, sustainably, and at a cost businesses can justify.